The real power of machine learning may have nothing to with automating music making, and everything to do with making sound tools hear the way you do.
There’s a funny opening to the release for Deezer’s open source Spleeter tool:
While not a broadly known topic, the problem of source separation has interested a large community of music signal researchers for a couple of decades now.
Wait a second – sure, you may not call it “source separation,” but anyone who has tried to make remixes, or adapt a song for karaoke sing-alongs, or even just lost the separate tracks to a project has encountered and thought about this problem. You can hear the difference between the bassline and the singer – so why can’t your computer process the sound the way you hear? Splitting stems out of a stereo audio feed also demonstrates that tools like EQ, filters, and multiband compressors are woefully inadequate to the task.
Here’s where so-called “AI” is legitimately exciting from a sound perspective.
It’s unfortunate in a way that people imagine that machine learning’s main role should be getting rid of DJs, music selectors, and eventually composers. And that’s unfortunate not because the technology is good at those things, but precisely because so far it really isn’t – meaning people may decide the thing is overhyped and abandon it completely when it doesn’t live up to those expectations.
But when it comes to this particular technique, neural network machine learning is actually doing some stuff that other digital audio techniques haven’t. It’s boldly going where no DSP has gone before, that is. And it works – not perfectly, but well enough to be legitimately promising. (“It will just keep getting better” is a logical fallacy too stupid for me to argue with. But “we can map out ways in which this is working well now and make concrete plans to improve it with reason to believe those expectations can pan out” – yeah, that I’ll sign up for!)
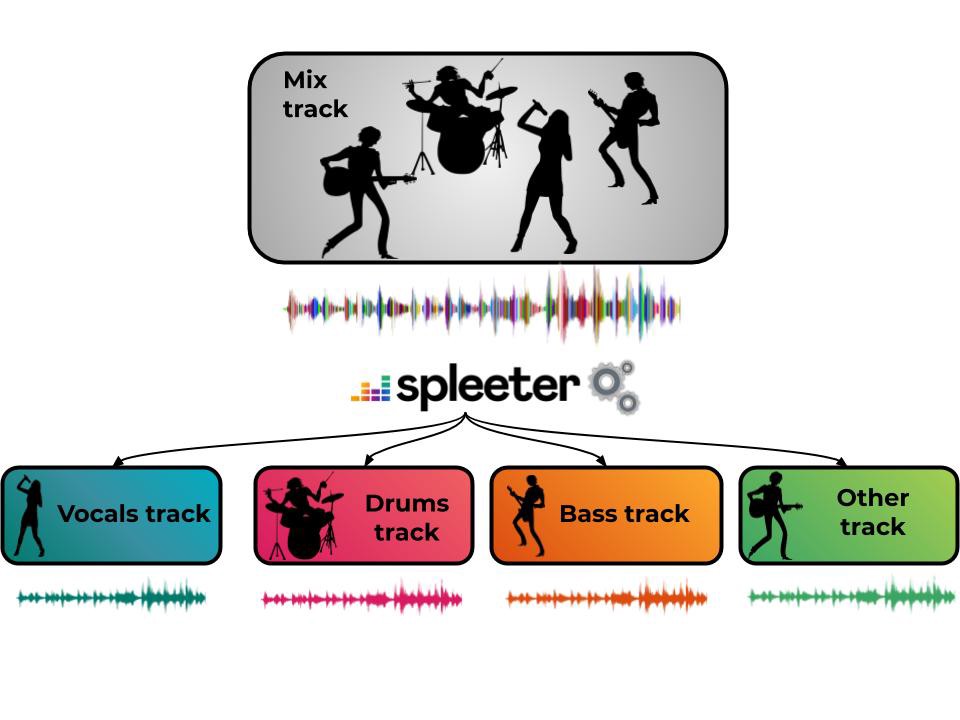
Spleeter from music streaming service Deezer (remember them?) is a proof of concept – and one you can use right now, even if you’re not a coder. (You’ll just need some basic command line and GitHub proficiency and the like.)
It’s free and open source. You can mess around with this without paying a cent, and even incorporate it into your own work via a very permissive MIT license. (I like free stuff, in that it also encourages me to f*** with stuff in a way that I might not with things I paid for – for whatever reason. I’m not alone here, right?)
It’s fast. With GPU acceleration, like even on my humble Razer PC laptop, you get somewhere on the order of 100x real time processing. This really demonstrations computation in a way that we would see in real products – and it’s fast enough to incorporate into your work without, like, cooking hot waffles and eggs on your computer.
It’s simple. Spleeter is built with Python and TensorFlow, a popular combination for AI research. But what you need to know if you don’t already use those tools is, you can use it from a command line. You can actually learn this faster than some commercial AI-powered plug-ins.
It splits things. I buried the lede – you can take a stereo stream and split it into different audio bits. And –
It could make interesting results even when abused. Sure, this is trained on a particular rock-style instrumentation, meaning it’ll tend to fail when you toss audio material that deviates too far from the training set. But it will fail in ways that produce strange new sound results, meaning it’s ripe for creative misuse.
Friend-of-the-site Rutger Muller made use of this in the AI music lab I participated in and co-facilitated in Tokyo, complete with a performance in Shibuya on Sunday night. (The project was hosted by music festival MUTEK.jp and curated by Maurice Jones and Natalia Fuchs aka United Curators.) He got some really interesting sonic results; you might, too.
Releasing Spleeter: Deezer Research source separation engine
Spleeter remains a more experimental tool and interesting for research. Commercial developers are building tools that use these techniques but develop a more practical workflow for musicians. Check, for instance, Accusonus – and more on what their tools can do for you as well as how they’re working with AI very soon.
Stop the presses! There’s more!
One development/research team quickly tweeted to point out they have their own tool. It might be better suited for CDM readers, because it is optimized to work on small data sets – which means it’s also suitable for training on your own audio, opening up additional musical and experimental possibilities.
https://t.co/lLq8UPxWsu
— Faro (@faroit) November 22, 2019
The PyTorch repo is the main one. There is also a Notebook and we currently prepare a python package with faster inference. But the whole point is: Open-unmix is focussed on simplified training. It's basically like an MNIST example
Check it out:
Open-Unmix – Music Source Separation for PyTorch
This is interesting enough that I may do a separate story on it, having missed it the first time, so stay tuned.
image credit:
Feature image is a series of posters dubbed Waveform – and really cool work, actually, if I found it accidentally! See the series on Behance; I think I need one of these on my wall.
“Waveform poster series 2017” by Robert Anderson is licensed under CC BY-NC-ND 4.0